Neural Network Explained: How They Work, Key Types and Applications

The Neural Network is a computational model crafted from many interconnected layers that can process your data, tweak internal weights, and learn patterns through repeated training.
This is what allows modern systems to deal with large volumes of data to perform the most accurate predictions, classify inputs, and support AI workloads.
Here at ServerMania, we provide the infrastructure organizations require to run demanding AI workloads through Dedicated Servers. We offer specialized GPU Servers for ultimate parallel processing or entire Server Clusters for enterprise.
These services give you reliable compute resources for training models, managing datasets, and deploying AI systems in production.
So, in this guide, we’re going to explain how neural networks function, the main architectures used in modern AI, and the roles they fill in production environments.
How Neural Networks Work
For a neural network to provide accurate predictions, it uses a structured layer process that transforms the input into a thoughtful output.
The system takes an input vector:
X = (x1, x2, x3 …) Then it passes it through several stages of computation, where each stage adjusts internal values to form patterns that support accurate decisions.
The core operation in each layer is the linear transformation:
Z = W·X + bHere, W represents the weights that decide how strongly each input influences the result, and b
represents the bias that shifts the neuron’s activation point. This transformation is what prepares the data for the nonlinear activation that follows.
The activation function shapes how the neuron responds, allowing the network to learn complex boundaries; therefore, during training, the model updates W and b many times.
The goal is to learn a function:
f(X) → YHere, X is the input, and Y is the predicted output. Over time, the model reduces its error and produces consistent results.
Here are the three main parts of a typical neural network.
1. Input Layer
The input layer receives the raw features
(X1, X2, X3 …)Each element in the vector represents one property of the sample. In a spam detection task, the features might be word counts, specific phrases, or metadata from the email. The input layer does not transform the data, as it only prepares it for the next stage.
2. Hidden Layers
These layers perform the main computation.
Z = W·X + bEvery neuron applies the formula and then passes Z through an activation function like ReLU, sigmoid, or tanh. Each layer creates new representations by mixing signals from the previous layer, while early hidden layers focus on basic patterns.
Later layers identify more structured relationships that guide the final decision!
3. Output Layer
This layer converts the final transformed values into a usable result.
f(X) → YFor classification, it often applies a function such as softmax to produce a probability distribution
For regression, it produces a numeric output. The output reflects the network’s learned function.
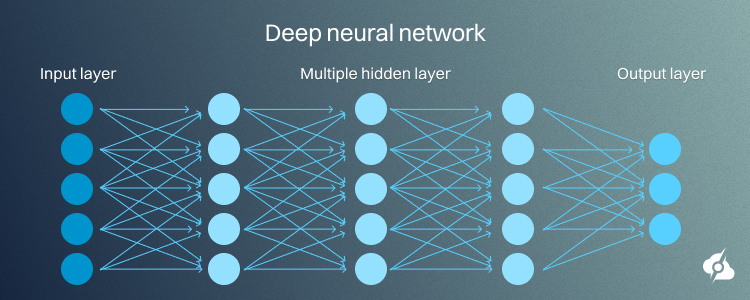
A neural network with multiple hidden layers.
See Also: What Is An AI Server?
Types of Neural Networks
There are several architectures of neural networks targeted at the solution of particular issues.
The structure, flow of data, and the learning mechanism varied in each kind of network, making it more applicable to a certain task that ranges from simple classification to many complex tasks related to image recognition, large language processing, and prediction over sequences.
A few of the most usable types of neural networks are the following:
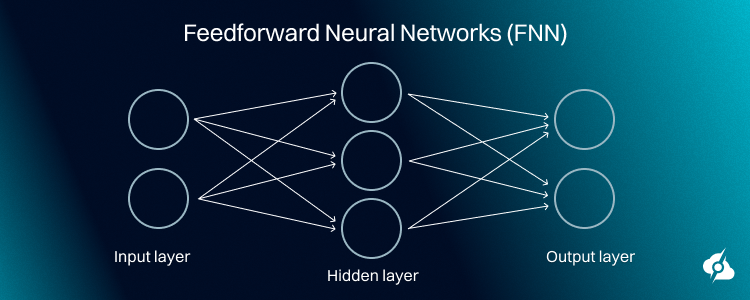
Feedforward Neural Networks (FNN)
In the Feedforward Network, considered to be the basic form of a neural network, the nodes are designed to propagate data directly from one layer to another.
There is no loop or cycle involved in it. Feedforward Network finds its major application in image classification and speech recognition.
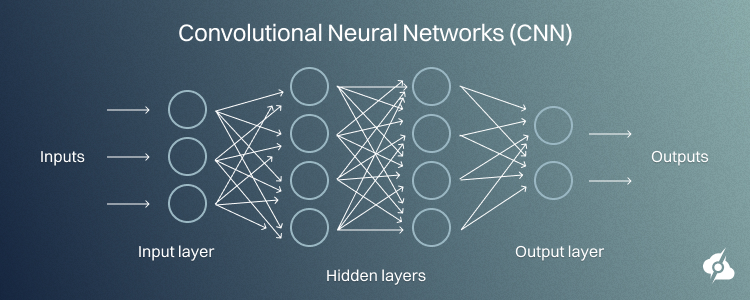
Convolutional Neural Networks (CNN)
Convolutional Neural Networks find applications in image processing and computer vision. They are made up of special layers known as convolutional layers, which have the inherent capability to view necessary features from an image, such as edges or textures.
This constitutes CNN as very powerful in the performance of such tasks as face recognition, object detection, and medical image analysis.
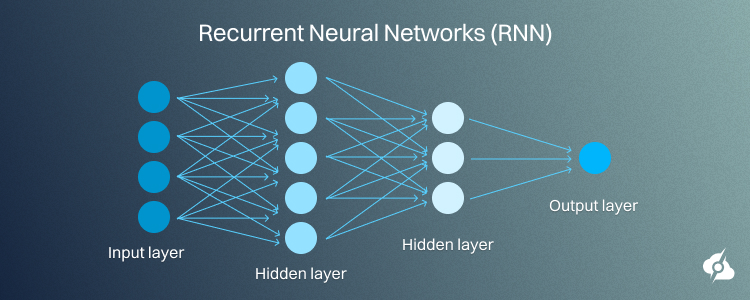
Recurrent Neural Networks (RNN)
Recurrent Neural Networks are for sequential data processing, for either temporal such as time series, or natural language.
Loops may also be an inherent part of their architecture, allowing information to persist across time steps. That is why speech recognition, language modeling, and time-series forecasting are ideal applications for them.
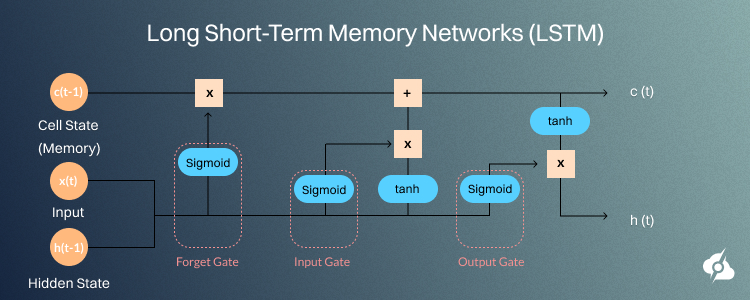
Long Short-Term Memory Networks (LSTM)
A Long Short-Term Memory is a special type of RNN that can learn long-term dependencies. Their applications are especially appropriate for cases with the need to consider context over longer spans of time, such as in language translation and many speech-to-text applications.
See Also: NPU vs GPU: Choosing The Right AI Hardware
Neural Network Training
Neural Network training is the process that enables turning random behavior into meaningful output, prediction, and decisions. When a network is first created, its weights and biases start with arbitrary values. At that stage, the model has no understanding of the patterns in the data.
The training gives the network a way to study examples, measure its mistakes, and update its internal parameters so its predictions gradually improve. Through repeated exposure to labeled samples, the network learns how inputs should map to outputs.
Training starts with a simple computation inside each neuron!
The neuron forms a weighted sum of its inputs:
z = Σᵢ (wᵢ xᵢ) + bthen applies an activation function…
a = σ(z)Here, xᵢ represents an input feature, wᵢ is its weight, b is the bias term, z is the linear output, σ is the activation function, and a is the neuron’s final value. This combination lets the network turn raw input X into a prediction Y through a series of linear steps followed by nonlinear activations.
The strength of a neural network comes from its ability to learn appropriate values for wᵢ and b. The network compares a prediction Ŷ with the true label Y and measures the difference through a loss function. So, this loss reflects how far the predicted probability is from the correct class.
Training uses backpropagation to reduce this loss. The process follows four stages.
| Step | Description |
| Forward Pass | Inputs move through the layers. Each neuron computes z, applies σ, and sends its output to the next layer. |
| Loss Calculation | The model measures how far Ŷ is from Y using the selected loss function. |
| BackwardPass | The error signal flows backward. The algorithm determines how much each weight and bias contributed to the final error using the chain rule. |
| Parameter Update | Weights and biases are adjusted to reduce the loss. Gradient descent guides these updates toward a point where the loss reaches its minimum. |
The training cycles through these steps many times. Each cycle tunes the parameters so the network’s output aligns more closely with the correct answer. With enough data and iterations, the parameters settle near values, producing predictions on both training and unseen samples.
See Also: LPU vs GPU: Choosing an AI Processor
Applications of Neural Networks
Neural networks find application in a wide range of systems by learning patterns and then fully transforming them into meaningful data.
Their ability to extract a structure from images, text, signals, and time series has made them central to modern AI. Industries use them to automate decisions, predict outcomes, and analyze information at scales that manual methods cannot handle.
The examples below show how different sectors apply these models to solve practical problems.
- Manufacturing: Systems forecast equipment failure, optimize production schedules, and improve supply chain planning.
- Retail: Models personalize product recommendations, forecast demand, and guide pricing decisions.
- Science and Technology: Networks study complex datasets, simulate physical systems, and support research in physics, chemistry, and biology.
- Cloud Computing: Models predict load, allocate resources efficiently, and detect unusual activity for stronger security.
- Complex Systems: Networks reveal nonlinear relationships in climate, economic, and social models to support long-term predictions.
- Computer Vision: CNNs identify objects, process medical scans, and support autonomous navigation.
- Natural Language Processing: Transformers handle translation, summarization, and conversational tasks.
- Speech Recognition: Deep models convert audio into text for voice assistants and communication tools.
- Forecasting and Time Series: Models track trends for demand planning, finance, and weather prediction.
- Reinforcement Learning: Neural networks guide agents in robotics, gaming, and autonomous control.
- Pattern Recognition: Systems classify documents, detect anomalies, and sort signals across large datasets.
Did You Know❓
Neural networks often outperform many traditional models in tasks where patterns are hard for humans to define. For example, vision models can detect tiny anomalies in medical scans that radiologists overlook, while language models track subtle context shifts across long documents.
See Also: How to Set Up and Optimize GPU Servers for AI Integration
Why Choose ServerMania for AI & Machine Learning?
AI and ML workloads require stable throughput and fast data access, which requires hardware that remains consistent under heavy demand.
Here at ServerMania, we can provide tailored infrastructure that will provide you with the HW resources you need to train models, run experiments, and deploy production-ready systems.
The solutions below offer reliable performance for projects of any scale:
Dedicated Servers
Dedicated Servers supply isolated compute power for training and inference workloads. They deliver predictable performance and allow control over configuration, storage, and networking.
This makes them a dependable option for teams that need consistent, uninterrupted resources.
GPU Server Hosting
GPU Server Hosting accelerates training by handling large batches and complex computations. These systems reduce the training time and support tasks involving vision, language, and deep learning. They are designed for workloads that require high throughput and efficient processing.
Server Clusters
GPU Server Clusters offer distributed training and data operations. They link multiple machines into a unified environment that scales with project needs. This approach helps naby teams run intensive loads, heavy traffic, and maintain performance as models grow in size and complexity.
See Also: What is the Best GPU Server for AI and Machine Learning?

How to Get Started in 3 Steps:
Setting up the right infrastructure begins with understanding your project’s technical needs. ServerMania offers clear paths for teams that want reliable environments for training, deployment, and experimentation.
1️⃣ Evaluate Your Workload
Review the size of your datasets, the complexity of your models, and the expected runtime. This helps determine whether you need CPU system, GPU acceleration, or distributed resources.
2️⃣ Check Available Services
Compare Dedicated Servers, GPU Server Hosting, and Server Clusters to find the best fit for your training pipeline and deployment plans. Each service supports different performance loads.
3️⃣ Contact Customer Support
Reach out to ServerMania’s 24/7 support team or schedule a free consultation with AI and ML specialists. We will help refine the workload setup and guide you toward the ideal configuration.
We’re available right now!
Was this page helpful?
About the author

